
PolySubstance Use data Mining for Associations and Transitions (PSUMAnT)
Identifying patterns of Polysubstance Use is a key problem, particularly in large datasets such as the National Survey on Drug Use and Health (NSDUH). In this project, Dr. Saumyadipta Pyne led the development of a platform called PSUMAnT. This platform computes weighted support for the use of every combination of one or more substances, termed as a drugset, by individuals in the National Survey on Drug Use and Health data over the period 1965-2014. It uses an efficient bitstring representation with exact and approximate string-matching capabilities to search for patterns of association between drug sets and demographics of user groups at different time-intervals. Computation of weighted supports over time for every possible combination of substances in the survey, and their association with specific user groups, allows PSUMAnT to generate and test novel, interesting hypotheses in polysubstance use. PSUMAnT can be used for mining combinations of substances used among diverse demographic groups including those that have received less attention in this problem..

A New Game Theoretic Approach for Data Fusion
The statistical file-matching problem is a data integration problem with structured missing data. When multiple datasets of a phenomenon have observations on only partial subsets of variables, then the imputation of missing data is difficult as the over-arching model given by the joint distribution of all variables is nonidentifiable. The identification problem was studied using game theory using a general characterization of the minimax optimal strategy for Gaussian and non-Gaussian models (Computational Statistics & Data Analysis, 2022). Image courtesy: Wikipedia.

A New Platform for Modeling of Structural Phenotypes in the Eye
The structural degeneration in optic neuropathies such as glaucoma is characterized by neuroretinal rim (NRR) thinning of the optic nerve head and other clinical parameters. Dr. Saumyadipta Pyne led an international team to develop a new computational platform CIFU for circular functional analysis of OCT data for precise identification of structural phenotypes in the eye. Their analysis of novel high-resolution circular measurements on NRR phenotypes of nearly 4000 eyes from a clinical cohort was published in Scientific Reports (2021).
Computational Advances in Data Fusion Methods
Data fusion is the process of integrating multiple data sources to produce better inference than that provided by any individual source. The statistical file-matching problem aims to characterize the joint distribution of a full set of variables when only partial subsets of marginal distributions were actually observed. Dr. Saumyadipta Pyne and his collaborators at the University of Queensland published a new algorithm for data fusion using factor analysis and low-rank matrix completion (Statistics & Computing, 2021). They also introduced a novel Game Theoretic approach for statistical file-matching of non-Gaussian data (Computational Statistics & Data Analysis, 2021). Image courtesy: Wikipedia.

Calculating Probabilities of Environmental Extremes
Environmental researchers often encounter the problem of determining the probability of extreme events marked by exceedance of a high threshold of a variable of interest such as rainfall or air pollution. However, the available data may consist of observations that are much smaller than the threshold. This generic problem was addressed by Dr. Saumyadipta Pyne and his collaborators at University of Maryland and NASA in their study published in the International Journal of Statistics in Medical Research (2021). Image courtesy: NASA
Data fusion peeks beyond the usual range of surveillance
In disease modeling, a key statistical problem is the estimation of tail probabilities of health events from given data sets of small size and limited range. This particularly affects the surveillance of communicable diseases that have few cases in general but may resurge after a period of time. By fusion of data from neighboring counties, Dr. Saumyadipta Pyne and his collaborators at University of Maryland modeled the regional outbreaks of pertussis in Washington state in 2012, which was published in Entropy (2021 Special Issue on Modeling and Forecasting of Rare and Extreme Events). Image courtesy: CDC.

A new algorithm for small area estimation of health risk
While essential for policy-making, it reliable local estimates are difficult to compute from a survey due to the limited sample size of a typical "small area". Drs. Saumyadipta Pyne and Shaina Stacy, and collaborators, designed a new 2-step method for spatial re-scaling of survey data (using the Behavioral Risk Factor Surveillance System) thereby allowing the use of local covariates to produce precise smoking rate of every census tract in Allegheny County, PA. (Image courtesy: Wikipedia)

Identifying Patterns of Social Media Use Associated with Loneliness and Health
Long before the COVID-19 pandemic made the world acutely aware of the impact of social isolation on individual health and behavior, the "loneliness epidemic" had emerged as a persistent challenge in many societies in the developed world. By analyzing a large nationwide loneliness survey in the U.S. conducted by Cigna, Drs. Saumyadipta Pyne, Pedram Gharani, Meghana Desai, and their coauthors, identified differential patterns of social media use associated with loneliness and health outcomes in selected socio-economic groups as published in the Journal of Technology in Behavioral Science, 2021. (Image courtesy: Wikipedia)

International Consortium to study Developmental Origins of Diseases
Developmental Origins of Health and Disease (DOHaD) emphasizes the role of prenatal and perinatal exposures, such as undernutrition, in determining the development of human diseases in adulthood. The Healthy Life Trajectories Initiative (HeLTI) is an international consortium set up by the Canadian Institutes of Health Research with its counterparts in India, South Africa, and China (in collaboration with WHO) to conduct DOHaD trials in 4 countries. The goal of the study (published in BMJ Open) is to generate evidence to inform international policy and decision-making for the improvement of health and the prevention of non-communicable diseases. Dr. Saumyadipta Pyne is a co-PI of the consortium. (Image courtesy: HeLTI)
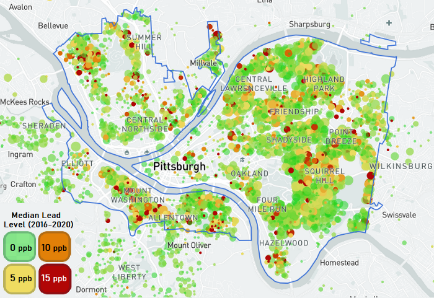
Local Risk Modeling of Lead in Drinking Water
ead contamination of drinking water is a prominent public health challenge in the United States. Yet, often it is difficult to precisely determine its variable exposures at local levels, especially in old cities. A recent study by Raanan Gurewitsch with Saumyadipta Pyne and coauthors introduced the concept of "infrastructural complexity" of a neighborhood to address this key issue. Their work on "Spatial modeling of lead water contamination risk in local communities of Pittsburgh, PA" was accepted for presentation in the student poster award and excellence in environmental justice track of the American Public Health Association annual meeting (APHA 2020).
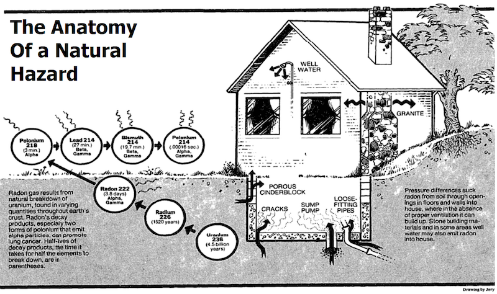
A Novel Application of Augmented Reality to Statistical Inference
In 1984, the "Watras incident" drew media and congressional attention in the U.S. when radon, a carcinogenic gas, at the Watras family home on the Reading Prong in Pennsylvania was recorded as almost 700 times the safe level, a lung cancer risk equivalent of smoking 250 packs of cigarettes a day! Combining synthetic data with real data, i.e., Augmented Reality (AR), can provide key insights into different phenomena. In a new study (published in JSTP), Saumyadipta Pyne and Prof. Benjamin Kedem of University of Maryland developed an AR approach for estimation of tail probabilities of rare events such as unusual environmental exposures or weather extremes or disease outbreaks from a moderate number of observations. (Image courtesy: NY Times)
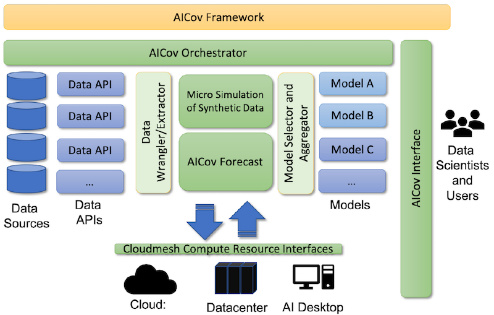
AICoV: A New Deep Learning Framework for COVID-19
A new Long short-term memory (LSTM) based artificial recurrent neural network architecture called AICov (published in J. Data Science) was developed as an integrative deep learning framework for COVID-19 forecasting with population covariates. Saumyadipta Pyne and his collaborator Prof. Geoffrey Fox at Indiana University, Bloomington, and coworkers integrated multiple different strategies based on LSTM into AICov to not only include data on the disease but, additionally, socioeconomic covariates and various risk factors at a local level. The compiled data are fed into AICov, leading to a powerful deep learning framework for improved outcome prediction.
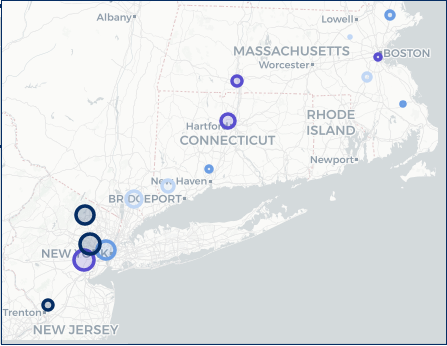
Modeling COVID-19 Death Rates in Populations with Comorbidities
Current evidence shows that prevalence of certain comorbidities in a given population could make it more vulnerable to serious outcomes of COVID-19, including fatality. A new mixture of polynomial time series (MoPTS) model was developed to simultaneously identify (a) clusters of U.S. cities in terms of their COVID-19 death rates, and (b) the different associations of those rates with some key comorbidities among the populations represented in the clusters. The study was conducted by Saumyadipta Pyne and collaborators (M. Maleki, R. Gurewitsch, M. Aruru, and G.J. McLachlan, University of Queensland).
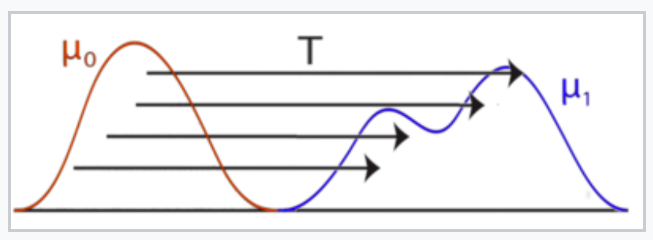
Identification of patterns linking human mobility and COVID-19 dynamics
The 18th century French mathematician Gaspard Monge, also considered the father of differential geometry, proposed Optimal Transport (OT) theory to determine the minimum effort to move or morph one distribution (say, a sand pile) into another (a fort for Napoleon's army!). By using OT to measure the minimum cost of translating a city's distribution of human mobility measures during the pandemic into that of its COVID-19 incidence, temporal patterns of such dependency across more than 150 U.S. cities were analyzed. The overall pattern in each of the identified clusters was summarized in the form of Wasserstein barycenters. The study (published in Sankhya) was conducted by Saumyadipta Pyne with Frank Nielsen of École Polytechnique, Gautier Marti and Sumanta Ray. Image courtesy: Wikipedia.
COVID-19 model for strategic lockdown policy
In 1957, M.S. Bartlett, FRS, introduced the concept of critical community size (CCS) below which an infectious disease does not persist in a closed population. With a subaward from a NIH Fogarty grant (PI: D. Burke, Co-PI: C. Bunker, S. Pyne) for training disease modelers in India, Prof. Indranil Mukhopadhyay and Sarmistha Das of Indian Statistical Institute, and their collaborators, used CCS to develop a model of strategic and focused lockdown policy for COVID-19 in a given population. Saumyadipta Pyne is a co-author of the study, which was published in 'Statistics and Applications' in June 2020. Image courtesy: Wikipedia.
Probabilistic Event Detection using Data Fusion
Dr. Saumyadipta Pyne and collaborators (Prof. Benjamin Kedem and Xuze Zhang, University of Maryland) have developed a new statistical framework for real and synthetic data fusion to estimate exceedance probabilities in an observed stream of events with only a few observations. Starting with a baseline distribution, this method can model a dynamic distortion of that original template, and thus, be used for modeling environmental exposures. The study was published in 'Applied Stochastic Models in Business and Industry' in June 2020, and covered in press. A follow-up study addressed the problem of model selection in such data fusion. Image courtesy: US EPA.
A Computational Model to Identify Rare Events in Big Data
Whether it is a forgotten shelf of classics in a large library, or a tiny collection of cells with special properties in our immune system, the presence of rare events in a large sample is often very hard to detect without precise guidance. The problem gets computationally even harder if the search space has many dimensions. Dr. Saumyadipta Pyne of PHDL led an inter-disciplinary team of researchers from Europe, Asia and the United States to develop an efficient solution using a Bayesian hierarchical model and powerful parallel inference.